Stochastische Dynamische Optimierung erlaubt die rekursive Berechnung optimaler Aktionen und ihrer Gewinnerwartungswerte in stochastischen Entscheidungsprozessen. Sofern dem Entscheider die Übergangswahrscheinlichkeiten unbekannt sind, können diese Bewertungen durch Reinforcement Learning mittels einfacher Updateregeln approximiert werden.
Stochastische Entscheidungsprozesse
Während Metaheuristiken meist eine stochastische Auswahl von Suchschritten durchführen, um ein (meist deterministisches) Optimierungsproblem durch Erreichung eines möglichst guten Endzustands einmalig zu lösen, zielt die Optimierung von Entscheidungsprozessen auf die Auswahl des optimalen Weges, unter der Annahme, dass nicht der Endzustand sondern die einzelnen Zustandsübergänge dem Entscheider einen (positiven oder negativen) „Reward“ bescheren, deren Summe es zu maximieren gilt. Erschwerend kommt häufig die Stochastik des Zustandsübergangs hinzu, d.h. in Abhängigkeit der (unbekannten) Umwelt kann das System bei Ergreifen der Aktion at im gleichen Zustand st in unterschiedliche Folgezustände übergehen.
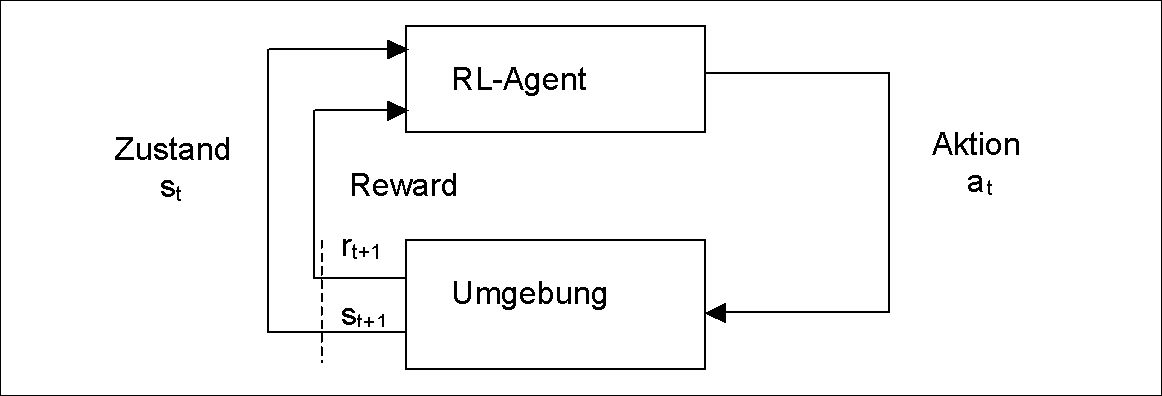
Abb.1: Bekräftigungslernender Agent in Interaktion mit seiner Umgebung
Rückwärtsrechnung: Stochastische Dynamische Optimierung
Sind die Übergangswahrscheinlichkeiten Pr{st+1=s’|st= s, at=a} dem Agenten bekannt, so kann er gemäß dem Bellmann’schen Optimalitätsprinzip die optimale Politik (also die Abbildung eines jeden Zustands auf die optimale Aktion) durch Rückwärtsrechnung rekursiv bestimmen: Für die letzte Stufe eines (endlichen) Entscheidungsprozesses kann die Bewertung V* t( s) eines jeden Zustands mit seinem erwarteten maximalen Gesamtgewinn bei optimaler Aktionsauswahl a* leicht erfolgen, auf der vorletzten Stufe verwendet man diese Bewertungen zur Bewertung jeder Aktion a in jedem Zustand s mit ihrem künftigen erwarteten Gesamtgewinn Qt-1( st-1, a t-1). Das jeweils Q(s,a) maximierende a* erlaubt dann die Bestimmung von V*t-1(s)=Q*t-1(s,a*) = maxa Q t-1(s, a) und so weiter.
Vorwärtsrechnung: Q-Learning
Kennt der Agent die Übergangswahrscheinlichkeiten nicht, kann er dieses Verfahren nicht anwenden, sondern muss die Aktions- und Zustandsbewertungen im Zeitablauf durch die wiederholte Durchführung des Entscheidungsprozesses erlernen. Selbst bei völlig falschen Ausgangswerten kann unter einigen (nicht sehr restriktiven) Annahmen gezeigt werden, dass folgende einfache Updateregel langfristig gegen die korrekten Werte für Q(s, a) konvergiert:
Q(s,a) := (1-alpha) Q(s,a) + alpha [reward + gamma max a Q(s a)]
Im Gegensatz zur Dynamischen Programmierung wird hier also nicht die optimale Aktion für jeden Zustand bestimmt, sondern vielmehr erfolgt ein iteratives Update der für ein Zustands-Aktions-Paar gespeicherten Bewertung immer dann, wenn diese Aktion a im betreffenden Zustand s gewählt wird und zwar anhand der (ebenfalls zumeist noch inkorrekten) Bewertungen des erreichten Folgezustand s. Dessen erwarteter Gesamtgewinn bildet (ggf. mit 0 < gamma <= 1 abdiskontiert) gemeinsam mit dem unmittelbaren reward den neuen Schätzwert für Q(s, a), der den alten Schätzwert aber nur als gewichtetes Mittel mit einer Lernrate von alpha verändert. Auch wenn die Aktionen zunächst basierend auf einer völlig falschen Bewertung ausgewählt werden, lässt sich zeigen, dass für eine hinreichend kleine Lernrate alpha dennoch Q gegen die korrekte Wertfunktion konvergiert. Allerdings darf hierfür nicht nur „greedy“ die in jedem Schritt scheinbar optimale Aktion a* gewählt werden, sondern mit einer geringen Wahrscheinlichkeit epsilon muss eine zufällige Aktion gewählt werden, um eine ständige Bekräftigung von suboptimalen Strategien durch mangelnde Exploration des Suchraums zu vermeiden. Leider gilt diese Konvergenz nicht unbedingt, wenn die Bewertungsfunktion Q bei großen (oder kontinuierlichen) Zustandsräumen zwecks schnellerem Lernen nicht für jedes Zustands-Aktions-Paar einzeln tabelliert wird, sondern z.B. mittels eines Neuronalen Netzes repräsentiert werden soll.
Literatur
Sutton,r R.S., Barto, A. G.: Reinforcement Learning: An Introduction. Cambridge (MA) 1998
