Durch die hochfrequente Abfolge von Bildern entstehen bei Videos sehr schnell hohe Datenvolumina. Bei der Kodierung ist daher eine Ausnutzung der räumlichen Redundanz (ähnliche Informationen zu benachbarten Bildpunkten in einem Bild) und der zeitlichen Redundanz (ähnliche Informationen in Folgebildern) wichtig.
Grundlagen
Ein Video stellt zunächst eine Sequenz von Frames (Einzelbildern) dar, die mit einem Verfahren wie JPEG zur Bilddaten-Kodierung komprimiert werden könnten. Hierdurch kann die räumliche Redundanz in den Bilddaten zur Kompression genutzt werden. Daneben besteht in einem Video aber auch eine zeitliche Redundanz durch die Ähnlichkeit der Daten von einem Frame zum nächsten. Um diese Redundanz ebenfalls auszunutzen verwenden Videoformate verschiedene Kodierungen für einzelne Frames:
-
I-Frames (intra-kodiert) – sind Frames, die mit einem Verfahren der Bildkodierung und damit ohne Ausnutzung der zeitlichen Redundanz kodiert werden. Diese Frames dienen u.a. als Aufsetzpunkte bei der Navigation in einem Video.
-
P-Frames (prädiktiv kodiert) – beziehen sich ggf. auf vorangegangene Frames. Konkret bedeutet dies, dass für die einzelnen Blöcke eines Frames (z.B. Blöcke von 8×8-Bildpunkten) nach einem möglichst gut übereinstimmenden Block im vorangegangenen Frame gesucht wird. Wird ein solcher Block gefunden, so wird der zu kodierende Block durch einen Bewegungsvektor (Positionsdifferenz zum passenden Block im vorhergehenden Frame) und Differenzinformationen für die Bildpunkte kodiert.
-
B-Frames (bidirektional prädiktiv kodiert) – verwenden Bezüge auf vorhergehende und nachfolgende I- und P-Frames. Grob gesprochen wird dabei der Mittelwert aus den am besten passenden Blöcken im vorhergehenden und im nachfolgenden Frame zur Vorhersage eines Blockes in einem B-Frame genutzt.
Für die Kodierung gibt es im Hinblick auf das Verhältnis zwischen den verschiedenen Framearten widerstrebende Ziele: Da die Kompressionsraten von I-Frames am schlechtesten sind, würde es sich anbieten wenige I-Frames zu verwenden. Andererseits benötigt man I-Frames aber z.B. als Ansprungstellen oder zur Vermeidung der langen Fortpflanzung von Übertragungsfehlern. In der Praxis verwendet man daher z.B. Framefolgen die nach dem Muster IBBBBPBBBBPBBBB aufgebaut sind und dann mit einem I-Frame wieder von vorne beginnen. Ferner werden bei der Datenübertragung diejenigen Frames zuerst übertragen, die zur Dekodierung der anderen Frames benötigt werden. Abbildung 1 verdeutlicht diese Zusammenhänge.
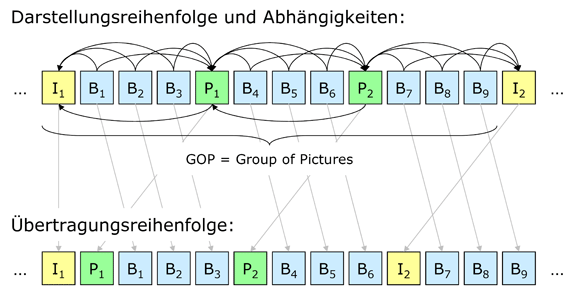
Abbildung 1: Nutzung der verschiedenen Framearten in einem Videodatenstrom
Die Qualität und die Kompressionsrate eines kodierten Videos hängen entscheidend von der Güte der Prädiktion ab. Ob sich gut passende Blöcke in benachbarten Bildern finden lassen hängt zum einen vom Inhalt des Videos ab, zum anderen verursacht die Suche nach passenden Blöcken natürlich erheblichen Aufwand, der z.B. beim Produzieren einer DVD besser geleistet werden kann als beim Abspeichern eines Videos auf der Festplatte eines Camcorders während der Aufzeichnung.
Standards und Formate
Federführend für die Standardisierung im Bereich der Videoformate ist die Moving Picture Experts Group (MPEG), eine Arbeitsgruppe der ISO/IEC. Diese hat eine Reihe von Standards entwickelt, die weit mehr als die eigentliche Kodierung der Bilddaten eines Videos definieren:
-
MPEG-1 – Standard, auf dem Produkte wie die Video CD und MP3 basieren. Erscheinungsjahr: 1993, Datenraten von ca. 1,5 MBit/s
-
MPEG-2 – Standard für digitales Fernsehen und DVDs. Erscheinungsjahr: 1994/95, Datenraten bis 15 MBit/s
-
MPEG-4 – Inhaltsrepräsentation wie MPEG-2, aber erweiterte Möglichkeiten durch Integration von 3D-Modellen (siehe Virtuelle Welten), synthetisches Audio … . Das Ziel von MPEG-4 ist, beliebige Multimediainhalte auf beliebigen Plattformen sowie eine Vielzahl von Medien, Profilen und Anwendungen zu unterstützen. Die eigentliche Kodierung der
Bilddaten ist in H.264/MPEG-4 AVC (Advanced Video Coding) spezifiziert. Erscheinungsjahr: 1998 (Erweiterungen in den Folgejahren)
-
MPEG-7 – ist kein Videoformat im eigentlichen Sinn sondern ein System zur Beschreibung von multimedialen Inhalten (Format für Metainformationen); Erscheinungsjahr: 2002
-
MPEG-21 – definiert eine interoperable Multimediainfrastruktur für die Verbreitung und Nutzung multimedialer Inhalte, insb. auch Digital Rights Management (DRM)
Dateiformate für Videos – wie z.B. Audio Video Interleave (AVI) von Microsoft – sind in der Regel Containerformate, in denen Audio- und Videodaten ineinander verzahnt („interleaved“) gespeichert werden. In einer Container-Datei können mehrere Video-, Audio- und Text-Datenströme (Untertitel) vorhanden sein, die mit verschiedenen Verfahren kodiert sind. Zum Kodieren und Dekodieren wird für jeden Strom ein entsprechender Codec benötigt. Beispiele für solche Codecs sind Indeo, Cinepak, Motion JPEG, MPEG-4 u.a.. Dabei gibt es eine Vielzahl von MPEG-2 oder -4 kompatiblen Codecs wie z.B. DivX von DivX, Inc.
Literatur
Henning, Peter A.: Taschenbuch Multimedia. 4. Auflage. München : Carl Hanser Verlag, 2007.
Chapman, Nigel ; Chapman, Jenny: Digital Multimedia. 2nd edition. Chichester : John Wiley & Sons, 2004