Unter Data Mining wird im weiteren Sinne der gesamte Prozess der Wissensentdeckung in großen Datenbeständen verstanden und im engeren Sinne nur die dabei verwendeten Analyseverfahren.
Data Mining vs. Knowledge Discovery in Databases
Data Mining ist ein interdisziplinäres Forschungsgebiet, in dem Experten aus den Bereichen Statistik, Informatik und Mathematik mit Wissenschaftlern des jeweiligen Anwendungsgebiets zusammenarbeiten. Zu den Hauptwerkzeugen gehören Verfahren der Statistik und Künstlichen Intelligenz (KI) sowie in zunehmenden Maße Visualisierungstechniken.
Data Mining steht dabei als Sammelbegriff für verschiedene rechnergestützte Verfahren, die zur Analyse großer Datenbestände eingesetzt werden. Decker und Focardi definieren Data Mining folgendermaßen [Decker, Focardi 1995, S. 3]:
“Data Mining is a problem-solving methodology that finds a logical or mathematical description, eventually of a complex nature, of patterns and regularities in a set of data.”
Data Mining zielt demnach darauf ab, Muster in einer Datenbasis zu finden, die mithilfe von logischen oder mathematischen Beschreibungen dargestellt werden können. Data Mining bietet im Gegensatz zu traditionellen statistischen Verfahren, die zur Überprüfung vorgegebener Hypothesen herangezogen werden, die Möglichkeit der automatischen Generierung neuer Hypothesen. Hier liegt auch der wesentliche Unterschied zum ‚maschinellen Lernen‘, das zwar einen stark deckungsgleichen Methodenkanon verwendet, aber weniger auf das Erkennen neuer Muster in Daten fokussiert als vielmehr auf die Entwicklung geeigneter Modelle zur Entdeckung bekannter Muster in neuen Daten. [Clarke 2009, S. 1f]
Data Mining ist Teil eines übergeordneten Prozesses, der als Knowledge Discovery in Databases (KDD) bezeichnet wird. Geprägt wurde der Begriff KDD durch Fayyad, der ihn wie folgt definiert [Fayyad et al. 1996, S. 6]:
“Knowledge Discovery in Databases describes the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.”
Eine zentrale Aussage ist, dass es sich um einen nichttrivialen Prozess (non-trivial process) handelt, dessen Ziel es ist, Muster (patterns) aus großen Datenbeständen (data) zu extrahieren. Diese Muster sollen zudem die Eigenschaften besitzen, dass sie für einen großen Teil des Datenbestandes gültig sind (valid) und bislang unbekannte (novel), potenziell nützliche (potentially useful) und leicht verständliche (ultimately understandable) Zusammenhänge innerhalb des Datenbestandes beschreiben.
Demnach ist Data Mining dem Verständnis von Fayyad folgend, lediglich der Teil des gesamten KDD-Prozesses, in dem die eigentliche Mustererkennung erfolgt [Fayyad et al. (1996, S. 9)].
Mittlerweile werden die beiden Begriffe Data Mining und Knowledge Discovery in Databases jedoch weitgehend synonym verwendet [Piatetsky-Shapiro 2007, S. 100].
Der neuere Begriff ‚Predictive Analytics‘ beschreibt im Wesentlichen die Anwendung von Data Mining mit besonderem Fokus auf die Generierung von Vorhersage-orientierten Modellen, wird jedoch in Teilen auch durch die stärkere Fokussierung auf statistische Methoden (im Gegensatz zur Orientierung an Datenbanken) begründet. [Felden, Koschtial, Buder 2012, S. 520f.]
Prozess nach Fayyad
Fayyad unterscheidet in seinem in Abbildung 1 dargestellten Prozessmodell fünf Phasen [Fayyad et al. 1996, S. 9].
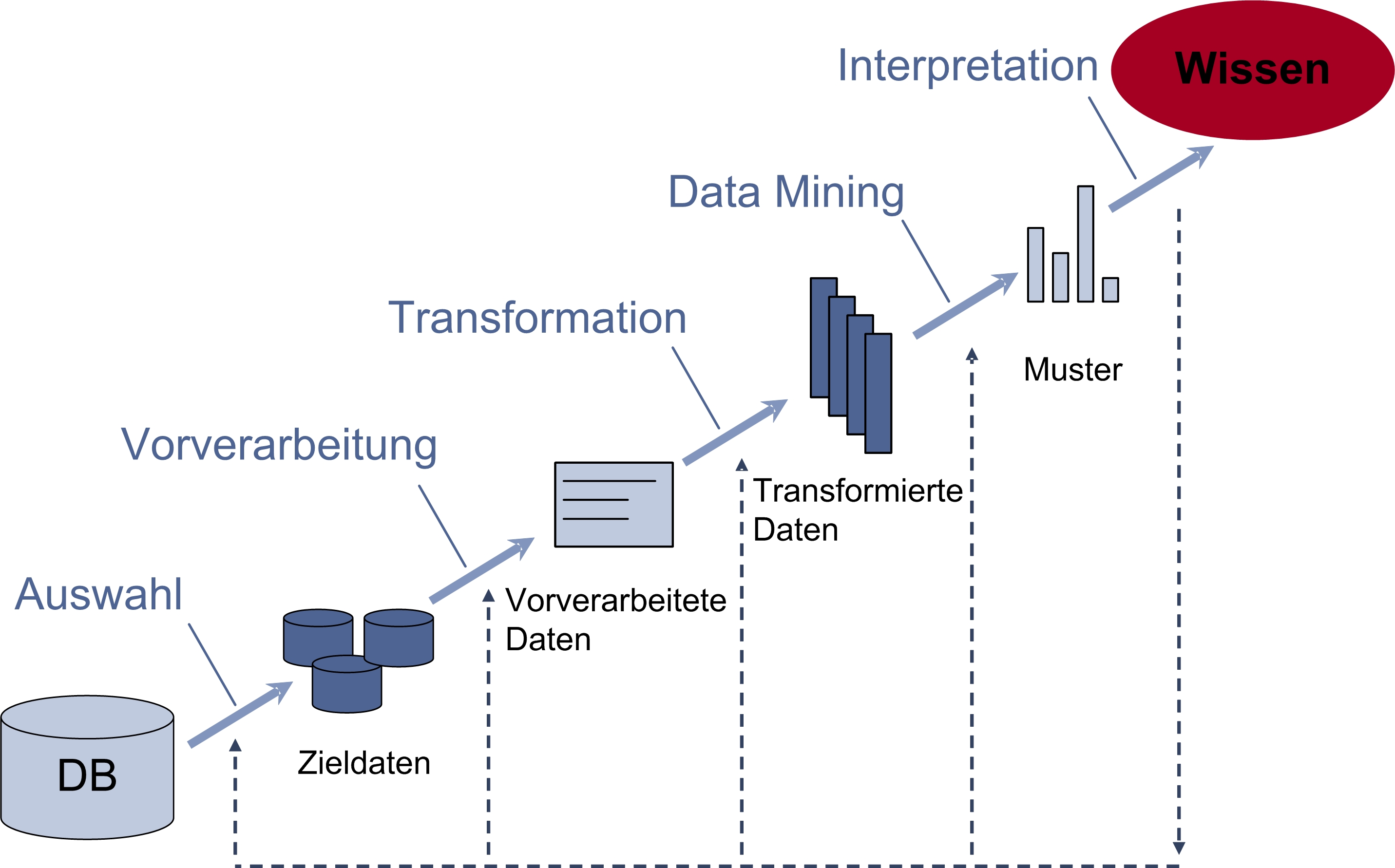
Abb. 1: KDD-Prozess nach Fayyad
In der ersten Phase des KDD-Prozesses nach Fayyad erfolgt die Auswahl des Datenbestandes, der für die gewählte Aufgabenstellung relevant ist. Dieser Zieldatenbestand wird dann in der Vorverarbeitungsphase bereinigt. Hierbei werden etwaige Datenqualitätsmängel beseitigt. Fehlende oder fehlerhafte Werte werden gegebenenfalls entfernt oder ersetzt. Zudem kann der bereits vorhandene Datenbestand in dieser Phase durch weitere Attribute angereichert werden, sofern es die jeweilige Aufgabenstellung erfordert. In der darauf folgenden Phase, der Transformation, wird der Datenbestand in die vom gewählten Analyseverfahren benötigte Form gebracht. Beispielhafte Transformationsschritte sind die Diskretisierung numerischer Werte oder die Umwandlung nominaler Werte in numerische Werte. Anschließend werden geeignete mathematische Verfahren angewendet, um die im Datenbestand vorhandenen, bislang unbekannten Muster zu erkennen. Erst durch die Interpretation der gefundenen Muster durch einen Experten entsteht Wissen, das auf die Verwendbarkeit hin zu evaluieren ist. Sollte die Aufgabenstellung mithilfe der gefundenen Muster nicht zufrieden stellend gelöst werden können, ist ein Rücksprung in eine der vorherigen Phasen zur Ergebnisverbesserung möglich [Fayyad et al. 1996, S. 9 ff.].
CRISP-DM
Im Gegensatz zum Modell von Fayyad ist der in Abbildung 2 [Jensen, K. 2016] dargestellte Cross-industry standard process for data mining (CRISP-DM) ein branchen- und anbieterneutraler Industriestandard, in dessen Mittelpunkt die betriebswirtschaftliche Problemstellung steht. Zudem wird der zyklische Charakter von Data-Mining-Projekten in den Vordergrund gerückt.
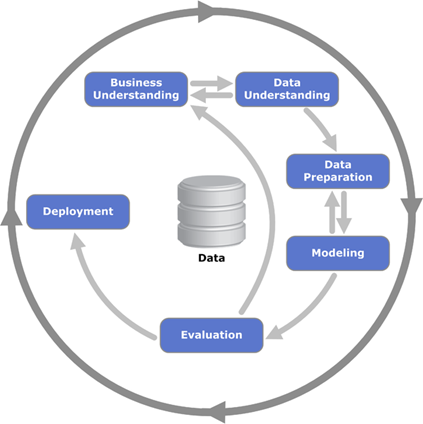
Abb. 2: CRISP-DM
Zu Beginn ist ein intensiver Austausch zwischen den Fachabteilungen und den mit der Durchführung der Analysen beauftragten Mitarbeiter nötig. Hierbei wird die zugrunde liegende Problemstellung erörtert (Business understanding) und die Zielsetzung des Data-Mining-Projekts festgelegt. Im Anschluss daran wird die zur Verfügung stehende Datenbasis dahingehend untersucht, inwieweit sie für die Lösung des betriebswirtschaftlichen Problems geeignet ist (Data understanding). Dabei sind Rücksprünge zur vorherigen Phase möglich. In der Phase der Datenaufbereitung (Data preparation) wird die Datenbasis von Datenqualitätsmängeln befreit und in Abhängigkeit von dem einzusetzenden Algorithmus transformiert. Durch den Einsatz von Data-Mining-Algorithmen in der Phase Modeling werden die Muster innerhalb des Datenbestandes erkannt und durch geeignete Modelle beschrieben. Diese Ergebnisse sind dann auf die anfangs festgelegten Anforderungen hin zu evaluieren (Evaluation). Erst nach einer erfolgreichen Evaluation wird das gewonnene Wissen für den weiteren Einsatz im Unternehmen zur Verfügung gestellt (Deployment) [Chapman et al. 2000, S.13].
Aufgabenbereiche
Die verschiedenen Data-Mining-Ziele können anhand unterschiedlicher Kriterien unterteilt werden. Nachfolgend wird die Einteilung in Klassifikation, Regression, Segmentierung und Abhängigkeitsanalyse verwendet.
Klassifikation
Ein Klassifikationsmodell ist eine Abbildung, die die Zuordnung von Elementen zu vorgegebenen Klassen beschreibt. Hierbei ergibt sich die Klassenausprägung der diskreten Klassifikationsvariablen aus den Ausprägungen der Attribute der Datenobjekte. Die Grundlage für ein Klassifikationsmodell bildet ein Datenbestand, dessen Datenobjekte jeweils einer vorgegebenen Klasse zugeordnet sind. Ein Klassifikationsmodell wird zur Prognose der Klassenzugehörigkeit von Datenobjekten eingesetzt, deren Klassenzugehörigkeit bislang nicht bekannt ist.
Regression
Mit einem Regressionsmodell wird eine abhängige, stetige Variable durch mehrere unabhängige Variablen erklärt. Es kann somit ebenfalls zur Prognose des unbekannten Wertes der abhängigen Variablen durch die Ausprägungen der zugehörigen unabhängigen Variablen eingesetzt werden. Der Unterschied zu einem Klassifikationsmodells liegt in der Kardinalität der abhängigen Variablen. Bei einem Klassifikationsmodell liegt eine diskrete, bei einem Regressionsmodell eine stetige Variable vor.
Segmentierung
Bei der Segmentierung werden Gruppen von Datenobjekten so gebildet, dass Objekte innerhalb einer Gruppe möglichst homogen sind, Objekte aus unterschiedlichen Gruppen jedoch möglichst heterogen sind.
Abhängigkeitsentdeckung
Bei der Entdeckung von Abhängigkeiten werden Abhängigkeiten zwischen Attributen oder einzelnen Attributsausprägungen erkannt, die innerhalb des Datenbestandes bzw. einer ausgewählten Teilmenge des Datenbestandes vorliegen. Ob tatsächlich ein kausaler Zusammenhang zwischen den entdeckten Abhängigkeiten vorliegt, muss im Anschluss an die Analyse evaluiert werden.
Verfahren
Zur Erreichung der oben aufgeführten Ziele des Data Mining stehen verschiedene Verfahren zur Verfügung. Im Folgenden werden ausgewählte Verfahrensklassen angesprochen.
Entscheidungsbäume
Ein typisches Verfahren zur Erstellung eines Klassifikationsmodells ist das Entscheidungsbaumverfahren. Zu Beginn wird der Datenbestand in eine Trainings- und eine Testmenge aufgeteilt. Der Trainingsdatenbestand wird dann sukzessive so aufgeteilt, dass disjunkte Teilmengen entstehen, die bezüglich der Klassifikationsvariablen möglichst homogen sind. Das Klassifikationsmodell wird durch eine Baumstruktur dargestellt, aus der Regeln zur Klassifikation von neuen Datensätzen abgeleitet werden können. Die Qualität des Modells wird anhand der Testmenge überprüft. Als Maß zur Beurteilung der Güte kann die Fehlklassifikationsquote der Testmenge bestimmt werden und das Modell gegebenenfalls angepasst werden.
Künstliche Neuronale Netze
Künstliche Neuronale Netze (KNN) bestehen aus einem Netzwerk von Neuronen und deren Verknüpfungen untereinander. Die Neuronen bilden Verarbeitungseinheiten, die eine Eingabefunktion, eine Aktivierungsfunktion und eine Ausgabefunktion enthalten. Die Eingabefunktion berechnet einen gewichteten Mittelwert der eingehenden Impulse. Dieser geht in die Aktivierungsfunktion ein, deren Wert mit einem vorgegebenen Schwellenwert verglichen wird und das Neuron bei Überschreiten aktiviert. Die Ausgabefunktion bestimmt den Wert, der nach Aktivierung an nachgelagerte Neuronen weitergegeben wird. KNN besitzen je eine Eingabe- und eine Ausgabeschicht sowie eventuelle verdeckte Schichten. Die Inputdaten werden in die Eingabeschicht eingespeist und die Ausgabeschicht liefert die Ausgabe des Netzes. Bei der Modellierung eines KNN werden zu Anfang die Anzahl, der Typ und die Anordnung der Neuronen sowie die Gewichtung der Verbindungen festgelegt. Das Modell wird dann anhand des Datenbestandes angepasst, indem die Gewichtungen der Verbindungen durch Lernregeln variiert werden. Künstliche Neuronale Netze werden sowohl zur Erstellung von Klassifikations- bzw. Regressionsmodellen eingesetzt als auch zur Clusterbildung.
Clusterverfahren
Clusterverfahren bilden anhand von Ähnlichkeits- bzw. Distanzmaßen Cluster von Datenobjekten, wobei Datenobjekte innerhalb eines Clusters möglichst homogen sind, Datenobjekte, die zu unterschiedlichen Clustern gehören, jedoch möglichst heterogen zueinander sind. Man unterscheidet hierarchische und partitionierende Clusterverfahren. Hierarchische Clusterverfahren fügen ausgehend von den einzelnen Datensätzen sukzessive jeweils zwei Cluster zusammen bis alle Datensätze in einem einzigen Cluster enthalten sind (agglomerative Verfahren), oder unterteilen ausgehend von einem einzigen Cluster, bestehend aus allen Datensätzen, schrittweise die Cluster, bis die Cluster aus jeweils einem Datensatz bestehen (divisive Verfahren). Partionierende Verfahren bilden für eine festgelegte Anzahl von Clustern eine (lokal) optimale Clusterung.
Assoziationsanalyse
Mithilfe der Assoziationsanalyse können Abhängigkeiten zwischen Attributen oder einzelnen Attributsausprägungen innerhalb eines Datenbestandes entdeckt werden, die durch Regeln der Form „Wenn X vorkommt, tritt auch Y auf“ beschrieben werden. Zur Bewertung einer Regel können unterschiedliche Interessantheitsmaße herangezogen werden, die auch zur Regelgenerierung genutzt werden können [Eigene Darstellung, basierend auf Beekmann, Chamoni 2006, S. 267 und Bange 2016, S. 125].
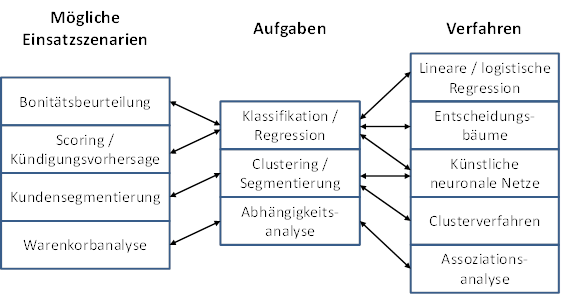
Abb. 3: Zuordnung ausgewählter Aufgaben und Verfahren
Literatur
Bange, C. (2016): Werkzeuge für analytische Informationssysteme. In: Gluchowski, P.; Chamoni, P. (Hrsg.): Analytische Informationssysteme. Business Intelligence-Technologien und –Anwendungen. Berlin : Springer: S. 97-126. DOI: 10.1007/978-3-662-47763-2_6
Beekmann, F.; Chamoni, P. (2006): Verfahren des Data Mining. In: Chamoni, P.; Gluchowski, P. (Hrsg.): Analytische Informationssysteme. Business Intelligence-Technologien und –Anwendungen. Berlin et al. : Springer: S. 263-282. DOI: 10.1007/3-540-33752-0_13
Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R. (2000): CRISP-DM 1.0 Step-by-step data mining guide, white paper, Chicago.
Decker, K.; Focardi, S. (1995): Technology overview: a report on data mining. Swiss Federal Institute of Technology (ETH Zurich) Technical Report CSCS TR-95-02, Zürich.
Fayyad, U.M.; Piatetsky-Shapiro, G.; Smyth, P. (1996): From data mining to knowledge discovery: An overview. In: Fayyad, U.M.; Piatetsky-Shapiro, G.; Smyth, P.; Uthurusamy, R. (Hrsg.): Advances in knowledge discovery and data mining. Menlo Park et al. : AAAI Press: S. 1-34. DOI: 10.1609/aimag.v17i3.1230
Felden, C., Koschtial, C., Buder, J. (2012): Predictive Analytics in der Strategischen Anlagenwirtschaft. In: Mertens, P., Rässler, S. (Hrsg.) Prognoserechnung, 7. Aufl. Physica, Berlin (2012): S. 519–537. DOI: 10.1007/978-3-7908-2797-2_22
Jensen, K. (o.J.): CRISP-DM Process Diagram. URL: https://commons.wikimedia.org/wiki/File:CRISP-DM_Process_Diagram.png, Abgerufen am 25.07.2016.
Piatetsky-Shapiro, Gregory (2007): Data mining and knowledge discovery 1996 to 2005: overcoming the hype and moving from “university” to “business” and “analytics”. In: Data Mining and Knowledge Discovery 15 (2007), Nr. 1: S. 99-105. DOI: 10.1007/s10618-006-0058-2