Bei der Function-Point-Methode handelt es sich im Kern um ein Verfahren zur Bestimmung des Umfangs und der Komplexität von Software. Die daraus resultierende Bestimmungsgröße Function Points lässt sich für verschiedene Zwecke verwenden. In einer traditionellen Anwendung werden Function Points für die Aufwandsschätzung von Software-Projekten herangezogen.
Grundprinzip der Function-Point-Methode
Das zentrale Konstrukt der Function-Point-Methode ist das abstrakte Maß Function Points (FP), mit dem der Umfang und die Komplexität einer Software ausgedrückt wird. Damit lassen sich Software-Projekte und -Produkte miteinander vergleichen. Kern der Methode ist, wie die Function Points zu bestimmen sind. Dafür werden bestimmte Zählregeln vorgegeben.
Die Function Points können als Ausgangsgröße verschiedenen Zwecken dienen. Ursprünglich wurden sie besonders im Zusammenhang mit der Aufwandsschätzung betrachtet, bei der von dem mit Function Points ausgedrückten Software-Umfang auf den für ihre Erstellung erforderlichen Aufwand geschlossen wird. Jedoch lassen sich Function Points auch für andere IT-Management-Aufgaben verwenden [Poensgen/Bock 2005, S. 6 ff].
Die Methode zur Ermittlung von Function Points und die darauf aufbauenden Schätzung des Projektaufwands geht zurück auf Allan J. Albrecht von der Firma IBM [Albrecht 1979, IBM 1985]. Aufgrund ihrer relativ einfachen Anwendbarkeit und der weitgehenden Loslösung von technischen Bezugspunkten hat sie in der Praxis eine gewisse Verbreitung erfahren.
Ermittlung von Function Points
Maßgebend für die Bestimmung von Function Points ist die fachliche Anwendersicht. Aus dieser Perspektive sind Elementarprozesse zu identifizieren, die durch die Software abgedeckt werden (sollen). In der Original-Terminologie wird von Funktionen gesprochen, was neben Datenmanipulationsoperationen (transactional functions) auch Datenbestände (data functions) meint. Jede berücksichtigte Funktion erhöht die Function Points des Projekts um einen bestimmten Betrag. Allerdings zählen Funktionen in dieser Rechnung nicht gleich, sondern werden in Abhängigkeit von der Einstufung in eine bestimmte Funktionskategorie und Komplexitätsklasse unterschiedlich gewichtet.
Funktionen werden nach bestimmten Kategorien unterschieden. Dies sind einerseits Eingaben, Ausgaben und Abfragen, andererseits interne Datenbestände und Referenzdateien. Zudem werden die Funktionen hinsichtlich ihrer Komplexität eingestuft. Die üblichen Ausprägungen sind einfach, mittel und komplex. Aus der Kombination dieser Merkmale ergeben sich 5 * 3 = 15 Fälle, in die Funktionen eingeteilt werden können. Jedem Fall ist ein bestimmtes Gewicht zugeordnet, was den Function Points der entsprechend eingestuften Funktionen entspricht. Die (unadjustierten) Function Points ergeben sich als Summe der gewichteten Funktionen.
Die ermittelten Function Points können noch mit einem Wertfaktor adjustiert werden. Darüber soll ausgedrückt werden, ob ein Projekt durch besondere Systemmerkmale als über- oder unterdurchschnittlich komplex anzusehen ist. Durch Multiplikation mit dem Wertfaktor resultiert ein Aufschlag bzw. Abschlag auf die unadjustierten Function Points. Das maximale Ausmaß der Veränderung der Function Points wird willkürlich festgelegt und beträgt üblicherweise +/- 35%.
Die Ermittlung von Function Points ist zwar rechentechnisch einfach, jedoch hinsichtlich der Identifikation der Funktionen und deren Bewertung keineswegs trivial. Um den Zweck der Vergleichbarkeit zwischen verschiedenen Projekten zu erfüllen, müssen die Ausführenden jeweils den gleichen Bewertungsmaßstab zugrunde legen. Als Grundlage dafür hat die International Function Point User Group (IFUP) ein verbindliches Regelwerk zur Ermittlung der Function Points erstellt, das mittlerweile Gegenstand der ISO-Norm IEC 20926 [ISO 2003] geworden ist.
Abbildung auf den Projektaufwand
Function Points lassen sich in Bezug zu anderen für Software-Projekte und –Produkte relevanten Größen setzen. In Relation zum Projektaufwand (häufig verkürzt auf Arbeitseinsatz, ausgedrückt in Personen-Monate) ergibt sich etwa ein Maß für die Produktivität der Software-Entwicklung. Für den Zusammenhang zwischen den eingesetzten Personen-Monaten und den damit erzielten Function Points wird typischerweise ein nicht-linearer Verlauf unterstellt, bei dem das Verhältnis zwischen den beiden Größen zunehmend schlechter wird (Abbildung 1).
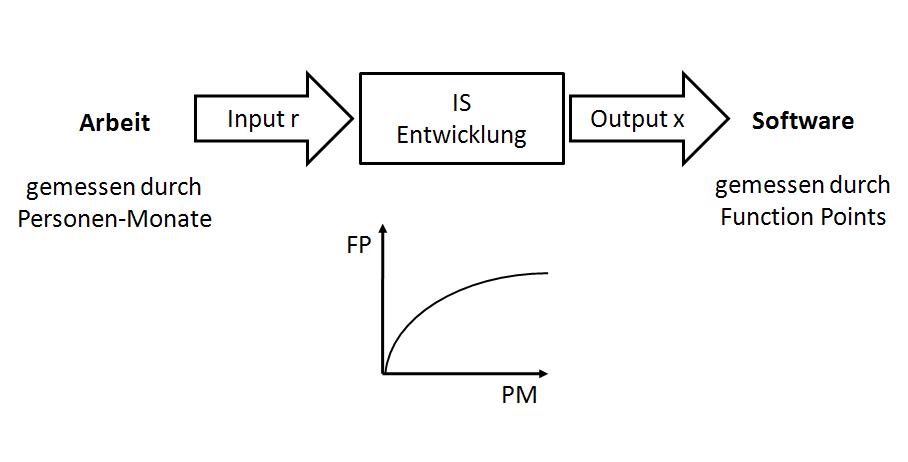
Abb 1.: Funktionaler Zusammenhang zwischen Softwareumfang und Projektaufwand
Derartige Abbildungsfunktionen lassen sich aus Daten vergangener Projekte ableiten, deren Input-Output-Relation bekannt ist. Davon ausgehend kann über einen Analogieschluss der Aufwand von Software-Projekten abgeschätzt werden. Dabei ist allerdings zu beachten, dass der fachliche Funktionsumfang nicht die alleinige Bestimmungsgröße für den erforderlichen Projektaufwand ist, sondern eine Reihe von weiteren Kostentreibern einen Einfluss haben. Nur wenn diese Einflussfaktoren bei den zu Grunde liegenden Altprojekten ähnlich ausfallen, wie in dem zu schätzenden Projekt, ist eine direkte Übertragung sinnvoll. Dies dürfte am ehesten dann der Fall sein, wenn die Schätzung anhand der Erfahrung aus eigenen Projekten erfolgen kann. Ansonsten ist bei diesem einfachen Ansatz mit Hinblick auf die Verläßlichkeit der Prognoseergebnisse große Vorsicht geboten.
Function Points können auch in spezifischen Verfahren der Aufwandsschätzung wie etwa COCOMO herangezogen werden [Poensgen/Bock 2005, S. 139 ff]. Bei diesen werden verschiedene Kosteneinflussgrößen explizit berücksichtigt, so dass die aufwandsrelevanten Spezifika eines Projektes sehr viel genauer abgebildet werden. Dadurch lassen sich Erfahrungen aus vergangenen Projekten zuverlässiger auf aktuelle Projekte übertragen.
Literatur
Balzert, Helmut: Lehrbuch der Software-Technik: Basiskonzepte und Requirements Engineering. 3. Auflage. Heidelberg: Spektrum 2009, S. 527 ff.