ETL steht für Extrahieren, Transformieren und Laden von Daten aus einem oder mehreren Quellsystemen in einen Zieldatenbestand inkl. Data Cleansing. ETL-Systeme bilden beim Data Warehousing die Datenschnittstelle zwischen operativen / externen Datenbeständen und Data Warehouse / Data Marts.
Grundlagen
Zentrale Aufgabe des Informationsmanagements ist, den Mitgliedern einer Organisation jene Informationen bereitzustellen, die sie zur Wahrnehmung ihrer Aufgaben benötigen. Sie sollen in den Stand versetzt werden, relevante Informationen zu erkennen und adäquat zu interpretieren. Je nach Erkenntniszielen und Informationsbedarfen müssen Daten unterschiedlicher Syntax und Strukturen eruiert, in ihrer Semantik erfaßt, integriert und auf semantisch höhere Ebenen transformiert werden. Unter Business Intelligence (BI) wurden hierfür Konzepte, Methoden und Verfahren entwickelt.
Die unterschiedlichen Anforderungen an die Datenhaltung und Informationsintegration bei operativen Systemen und BI-Systemen führten zur Trennung von Transaktionsdatenbanken und Data Warehouse (vgl. [Devlin, Murphy 1988]). Folgende Schichten werden unterschieden:
-
Source Database Layer mit Quelldaten aus operativen (Enterprise Resource Planning-) Systemen, externen Informationsdiensten oder dem WWW
-
Information Access Layer mit materialisierter Informationsbereitstellung in Data Warehouse / Data Marts oder Anfragen an verteilte Datenbestände über Mediatoren
-
Data Access and Integration Layer als Schnittstelle zwischen Source Database und Information Access Layer.
-
Meta Data Layer mit Daten für den Build Prozeß, Kontrolldaten über Build- und Runtime-Prozeß sowie Anwenderinformationen zur Systemnutzung.
Bei einer materialisierten Datenextraktion, -integration und -aggregation wird zwischen den Phasen Extraktion, Transformation und Laden unterschieden und der Data Access und Integration Layer durch ETL-Systeme realisiert. Erste Ansätze gehen auf [Stecher, Hellemaa 1986] zurück. In einer föderierten Unternehmensarchitektur (siehe Wikipedia, Stichwort „Federal enterprise architecture“) können ETL-Prozesse auf den Ebenen der „Enterprise Architecture“ in ein Data Warehouse, der „Segment Architecture“ in ein Data Mart und der „Solution Architecture“ in eine lokale Datenhaltung erfolgen. So erlaubt das Add-In PowerPivot von Excel 2010 ETL-Prozesse aus mehreren Quellen.
ETL-Prozess
Extraktion
Aus unterschiedlichen Quelldatenbeständen (relationale Datenbanken, File-Systeme, XML-Dokumente/Datenbank, Textdateien etc.) werden Daten extrahiert und in den Staging Area geladen. Die Extraktion kann auf 3 Arten initiiert werden:
-
Offline aufgrund festgelegter, an den betrieblichen Anforderungen orientierten Regeln, i.a. in periodischen Abständen
-
On Demand durch Anwendungen auf Data Warehouse / Data Marts
-
Realtime ereignisgesteuert durch Quelldatenträger.
Bei der Extraktion werden die Datenprofile entweder anhand von Metadaten (Metadatenmanagement) über die Quellen oder spezifischer Prüfmethoden (Data Profiling) ermittelt und als ungeeignet erkannte Quelldaten zurückgewiesen.
Transformation
Die Phase Transformation dient ebenso der Datenintegration. Das Mapping der Quelldaten auf die Zieldaten bestimmt den Funktionsumfang, z.B.:
-
Auswahl der relevanten Daten, Elimination von Duplikaten
-
Schlüsselvergabe/-bereinigung
-
Überführung von CSV (Comma Seperated Value) -Dateien in strukturierte Formate, XML/SQL-Konversion (XML, Structured Query Language)
-
Datenbereinigung, Integritätstests aufgrund Domänen oder vorgegebenen Mustern, Datenabgleich (Data Cleansing)
-
Überführung ereignisorientierter in periodenorientierte Größen, Währungsumrechnung, Aggregation, Kennzahlenermittlung u.a.
-
Datenintegration unterschiedlicher Quellen, Standardisierung, Datenergänzung (Datenfusion).
Konzepte zur Filterung, Harmonisierung, Aggregation und Anreicherung (Information Enhancement) finden sich in [Kemper, Finger 2010]. Die integrierten und transformierten Daten werden im Operational Data Store (ODS) [Kimbell, Caaserta 2004] abgelegt; auf ihn können ebenso OLTP- (Online Transaction Processing) Anwendungen zugreifen.
Laden
Aus dem ODS werden die Daten in das Zielsystem importiert. Der Import soll, da während dessen das Zielsystem blockiert wird, rasch und effizient erfolgen, indem z.B. nur Bereiche mit Änderungen überschrieben werden.
Kritische Erfolgsfaktoren
Qualität und Nutzen eines ETL-Systems werden, abgesehen von aufgrund Service Level Agreements (ITIL) einzuhaltender Performance, dadurch bestimmt, inwieweit sich unterschiedlich strukturierte, semantisch differierende Daten integrieren lassen. [Roth et al. 2002] schlagen die 3-Schichten-Architektur in Abbildung 1 vor. Foundation Tier umfaßt die Arbeitsspeicher sowie die Extraktions- und Konversionsfunktionen eines high-performance Datenbankmanagementsystems. Integration Services bilden die aus den betrieblichen Anforderungen abgeleiteten Datenselektions-, Transformations- und Integrationsfunktionen, auf welche die Standardapplikationen und Anfragesprachen (Structured Query Language) des Application Interface zugreifen.
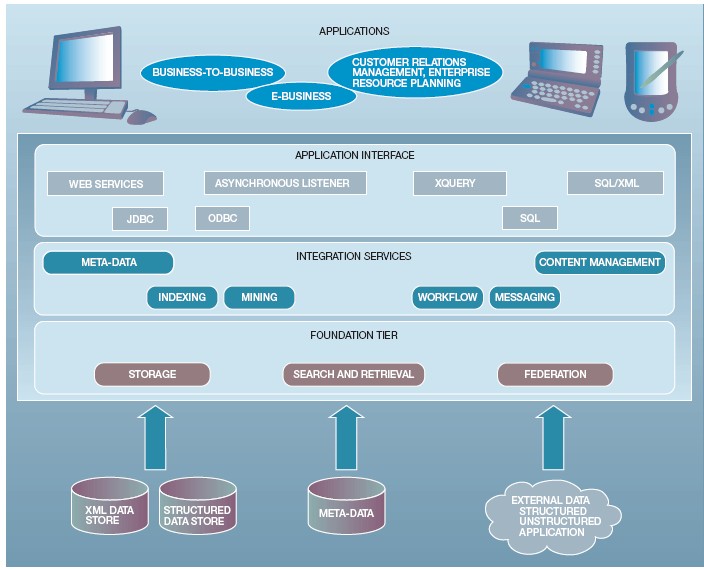
Abbildung 1: A three-tier information integration architecture [Roth et al. 2002, S. 570]
Literatur
Devlin, B.; Murphy, P.T.: An Architecture for a Business and Information System. IBM Systems Journal 27(1988)1, S. 60-80.
Kemper, H.-G.; Finger, R.: Transformation operativer Daten – Konzeptionelle Überlegungen zur Filterung, Harmonisierung, Aggregation und Anreicherung im Data Warehouse. In: In: Chamoni, P.; Gluchowski, P. (Hrsg.): Analytische Informationssysteme, 4. Aufl., Berlin/Heidelberg 2010, S. 159-174.
Kimball, R.; Caserta, J.: The Data Warehouse ETL Toolkit. John Wiley and Sons, 2004.
Roth, M.A.; Wolfson, D.C.; Kleewein, J.C.; Belin, C.J.: Information Integration: A new generation of information technology. IBM Systems Journal 41(2002)4, S. 563-577.
Stecher, P.; Hellemaa, P.: An “intelligent” extraction and aggregation tool for company databases. Decision Support Systems 2(1986)2, S. 145-158.
Wikipedia, Stichwort “Federal enterprise architecture”, Version vom 8.08.2012, 14:00, abrufbar unter http://en.wikipedia.org/wiki/Federal_enterprise_architecture.