Ein Clustering wird mit dem Ziel durchgeführt, die Datenobjekte einer gegebenen Objektmenge zu homogenen Klassen zu gruppieren. Die im Rahmen des Clustering eingesetzten Methoden lassen sich in hierarchische und partitionierende Clusterverfahren gliedern. Ein wichtiges Einsatzfeld liegt in der Marktsegmentierung. Moderne Methoden des Clustering sind die Mining-Verfahren.
Begriff und Einordnung
Unter Clustering wird eine Vorgehensweise verstanden, die mit Hilfe geeigneter Methoden die Klassenzugehörigkeit von Datenobjekten bestimmt. Die beim Clustering eingesetzten Methoden stellen neben den Künstlichen Neuronalen Netzen (KNN), den genetischen und evolutionären Algorithmen, den Entscheidungsbaumverfahren und den Assoziationsmethoden wichtige Verfahren des Data Mining dar. Als interdisziplinäres Forschungsfeld, das sich der Erkenntnisse verschiedener Wissenschaftsdisziplinen wie der Mathematik, Statistik oder Künstlichen Intelligenz (KI) bedient, liegt mit dem Data Mining ein Ansatz vor, der das Ziel verfolgt, in umfangreichen Datenbeständen, interessante Muster und Zusammenhänge zu erkennen, die sich zur Entscheidungsunterstützung und damit zur Vorbereitung von Handlungen nutzen lassen.
Das Ergebnis des Clustering ist die Ermittlung einer bestimmten Anzahl von Clustern, die auch als Gruppen, Kategorien, Klassen oder Segmente bezeichnet werden [Gluchowski, Gabriel, Dittmar 2008, S. 196]. Mit Blick auf diese Begriffe lässt sich der Vorgang des Clustering auch als Gruppierung, Kategorisierung, Klassifizierung oder Segmentierung bezeichnen. Kennzeichnend für die Cluster ist, dass sich die darin befindenden Datenobjekte hinsichtlich ihrer Merkmalsausprägungen durch eine hohe Ähnlichkeit bzw. Homogenität auszeichnen [Küsters 2001, S. 112]. Während die einzelnen Datenobjekte einer Klasse möglichst gleichartige Merkmalsausprägungen aufweisen, besitzen sie im Vergleich zu den Datenobjekten der anderen Klassen eine größere Unähnlichkeit bzw. Heterogenität [Bankhofer 2004, S. 398].
Da im Vorfeld einer Analyse keinerlei Informationen über mögliche Segmente existieren, sind die Anforderungen an das Modell- und Datenverständnis zu Beginn eines Clustering geringer als bei einer Klassifikation, die die Zuordnung von Datenobjekten zu vorgegebenen Klassen fokussiert [Gabriel, Röhrs 2003, S. 344]. Die im Rahmen des Clustering zum Einsatz kommenden Verfahren bieten die Möglichkeit, eine gewünschte Anzahl von Zielgruppen festzulegen. Andere Verfahren verzichten auf diese Vorgaben und ermitteln selbständig die Anzahl der Segmente aus dem Datenbestand heraus.
Ablauf und Methoden
Unter mathematischen Gesichtspunkten werden beim Clustering aus einer vorgegebenen Menge von Datenobjekten Teilgruppen unter der Bedingung gebildet, dass diese den vollständigen Lösungsraum ausfüllen. Der Ablauf einer Clusteranalyse vollzieht sich in drei Phasen.
Im ersten Schritt ist ein Proximitätsmaß auszuwählen, welches den Ähnlichkeitsgrad zwischen zwei Datenobjekten quantifiziert [Mertens, Wieczorrek 2000, S. 216]. Es lassen sich dabei zwei Arten von Proximitätsmaßen unterscheiden. Einerseits können Analysten auf die Gruppe der Ähnlichkeitsmaße zurückgreifen, welche die Ähnlichkeit bzw. Homogenität zweier Datenobjekte ausdrücken. Anderseits lassen sich Distanzmaße einsetzen, welche die Unähnlichkeit bzw. Heterogenität zweier Datenobjekte ermitteln.
Welches Proximitätsmaß für eine Clusteranalyse anzuwenden ist, hängt von den Eigenschaften und dem Skalenniveau der Merkmale der betrachteten Datenobjekte ab [Mertens, Wieczorrek 2000, S. 216f.]. Weisen die Variablen ein metrisches Skalenniveau auf, können Distanzmaße auf der Basis geometrischer Abstandskonstrukte, wie die euklidische Distanz oder die Blockmetrik, zum Einsatz kommen. Liegen die Variabeln nominalskaliert vor, können Maße verwendet werden, die auf die Identifizierung von Übereinstimmungen der einzelnen Merkmalsausprägungen ausgelegt sind [Küsters 2001, S. 112]. Darüber hinaus kann auch eine unterschiedliche Gewichtung der Merkmale eines Datenobjekts einen Einfluss auf das Ergebnis des Proximitätsmaßes ausüben. Nachdem ein geeignetes Proximitätsmaß bestimmt und die einzelnen Werte zur Ermittlung der Homogenität bzw. Heterogenität berechnet worden sind, folgt mit der Auswahl eines Fusionierungsalgorithmus der zweite Schritt einer Clusteranalyse.
Fusionierungsalgorithmen haben die Aufgabe, die Datenobjekte gemäß ihrer Ähnlichkeitswerte in Gruppen zusammenzufassen. Auch hier steht den Datenanalysten eine Reihe von Verfahren zur Verfügung, die sich anhand verschiedener Kriterien systematisieren lassen. Eine gebräuchliche Einteilung sieht, wie in Abbildung 1 veranschaulicht, die Systematisierung in hierarchische und partitionierende Verfahren vor [Bankhofer 2004, S. 398f.; Gluchowski, Gabriel, Dittmar 2008, S. 196f.; Markov, Larose 2007, S. 63ff.; Petersohn 2005, S. 91f.].
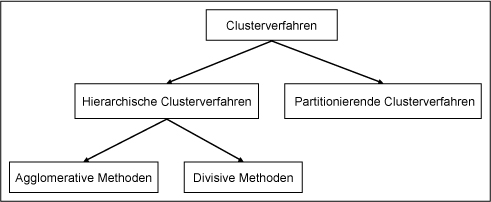
Abb. 1: Systematisierung der Clusterverfahren
Bei den partitionierenden Verfahren wird versucht, ausgehend von einer vorgegebenen Gruppeneinteilung, durch den iterativen Austausch der Datenobjekte zwischen den einzelnen Klassen die Gesamtlösung zu optimieren [Grabmeier 2001, S. 325ff.]. Damit eignen sich diese Verfahren insbesondere für Einsatzbereiche, bei denen bereits eine Clustereinteilung vorliegt. Hauptsächlich bei großen sowie wachsenden Datenmengen kann es in diesem Zusammenhang notwendig sein, bereits klassifizierte Datenobjekte hinsichtlich einer besseren Gruppenzugehörigkeit erneut zu prüfen. Je nach Ausprägung des eingesetzten Verfahrens erfordern einige partitionierende Algorithmen die Angabe einer maximalen Clusterzahl, während andere diese selbst ermitteln bzw. steuern. Eines der bekanntesten partitionierenden Clustermethoden ist das K-Means-Verfahren [Markov, Larose 2007, S. 69ff.].
Alternativ stehen den Datenanalysten hierarchische Verfahren zur Verfügung. Bei diesen Ausprägungen einer Clusteranalyse ist keine Gruppeneinteilung vorgegeben, so dass die Anzahl der Klassen selbständig berechnet werden muss. Die agglomerativ-hierarchischen Verfahren, als eine Unterkategorie hierarchischer Clustermethoden, verfolgen einen Bottom-Up-Ansatz und gehen bei der Gruppierung von der kleinsten Partition aus. Dies bedeutet, dass jedes Datenobjekt zunächst einen Cluster repräsentiert und sukzessiv neuen, größeren Gruppen zugeteilt wird. Gebräuchliche Maße zur Berechnung der Ähnlichkeiten bzw. Distanzen der Variablen sind beispielsweise das Single Linkage-Verfahren sowie das Complete Linkage-Verfahren [Petersohn 2005, S. 92ff.]. Während im ersten Fall der geringste Abstand zwischen zwei Datenobjekten als Grundlage zur Klassenbildung verwendet wird, dient beim Complete Linkage-Verfahren der maximale Abstand zwischen zwei Datenobjekten als separierendes Kriterium. Weitere Methoden sehen die Bestimmung von Mittelwerten als Grundlage zur Berechnung der Distanz zwischen unterschiedlichen Datenobjekten bzw. Clustern vor (Average Linkage-Verfahren).
Im Gegensatz zu den agglomerativ-hierarchischen Verfahren beginnen die divisiv-hierarchischen Verfahren mit der gröbsten Partition. Diesem Top-down-Ansatz zufolge befinden sich alle Datenobjekte zunächst in einem einzigen Cluster. Anschließend erfolgt die Aufspaltung der Datenobjekte in homogenere Teilgruppen. Im Vergleich beider Ausprägungen einer hierarchischen Clusteranalyse ist zu konstatieren, dass agglomerative Verfahren schneller sind und daher in der praktischen Anwendung den divisiven Methoden vorgezogen werden.
Weitere Systematisierungskriterien betreffen die Eindeutigkeit sowie die Möglichkeit einer optionalen Zuordnung der Datenobjekte zu den Clustern. Bei einer disjunkten Gruppeneinteilung darf jedes Datenobjekt nur einer Gruppe angehören, bei einer nicht-disjunkten Klasseneinteilung ist auch eine überlappende Zuordnung von Datenobjekten zu mehreren Klassen möglich. Oftmals erweist es sich bei dem Einsatz eines streng partitionierenden Verfahrens als schwierig, ein Datenobjekt eindeutig einer Gruppe zuzuordnen. Als Ausweg bietet sich im Rahmen des »fuzzy clustering« die Zuweisung von Werten an, die den Zugehörigkeitsgrad einer Variablen zu einer Gruppe wiedergeben [Bankhofer 2004, S. 399; Küsters 2001, S. 113].
Mit Blick auf die Möglichkeit einer optionalen Zuordnung wird ferner zwischen exhaustiven und nicht-exhaustiven Verfahren unterschieden. Bei einer exhaustiven bzw. erschöpfenden Gruppierung werden alle Datenobjekte klassifiziert, während bei einer nicht-exhaustiven Gruppierung es möglich ist, dass Datenobjekte nicht gruppiert werden.
In der dritten Phase einer Clusteranalyse ist die Anzahl der Cluster festzulegen, welche sich mit Blick auf die Aufgabenstellung am besten verwenden lassen. Mit anderen Worten ist an dieser Stelle die Frage zu klären, nach welchem Fusionierungsschritt eine geeignete Clusterlösung erreicht ist [Klein 2005, S. 307]. Dabei gilt es, den Zielkonflikt zwischen der Homogenitätsanforderung, die tendenziell eine große Clusterzahl impliziert, und der Handhabbarkeit sowie Aussagefähigkeit der Segmente, die eher durch eine geringe Clusterzahl begünstigt werden, zu lösen.
Um die Qualität und damit die Anwendbarkeit der Klassenbildungen zu beurteilen, ist abschließend die Güte des Klassifikationsergebnisses zu bestimmen. Gebräuchliche Kriterien, die sich für diesen Zweck einsetzen lassen, stellen das Homogenitäts- bzw. Heterogenitätskriterium und der F-Wert dar [Petersohn 2005, S. 98f.].
Anwendungsbereiche
Das Clustering lässt sich zur Beantwortung verschiedener Fragestellungen einsetzen. Zur Verdeutlichung der Anwendungsmöglichkeiten einer Clusteranalyse wird in der Literatur vielfach das Beispiel der Marktsegementierung genannt, deren Ziel es ist, aus einem heterogenen Kundendatenbestand homogene Kundengruppen zu ermitteln, auf die sich gezielte Marketingmaßnahmen ausrichten lassen [Klein 2005, S. 307; Hippner, Schmitz 2001, S. 607ff.]. Als geeignete Attribute zur Bestimmung der Cluster kommen neben sozioökonomischen Kriterien die Verhaltens- sowie Einstellungsmuster potenzieller Kunden bzw. Kundengruppen in Frage, die sich z. B. als Ergebnis einer Kundenbefragung ergeben. In analoger Weise, wie Kunden anhand ihres Kaufverhaltens in homogene Kundengruppen segmentiert werden können, lassen sich beispielsweise Wettbewerber anhand ihrer strategischen Ausrichtung klassifizieren.
Weitere Anwendungsfelder liegen in der Produktentwicklung. Produkte, die anhand verschiedener Kriterien bewertet wurden, lassen sich mit Hilfe des Clustering in Produktgruppen segmentieren. Die aus der Clusteranalyse resultierenden Informationen liefern Ansatzpunkte zur „Optimierung“ der Produkteigenschaften bzw. der Produktqualität. Ebenso bietet der Gesundheitsbereich Möglichkeiten zum Einsatz einer Clusteranalyse. In diesem Zusammenhang lassen sich etwa anhand des Alters, des Geschlechts, des Blutdrucks und des Cholesterinwerts diverser Patienten typische Datenkonstellationen in Form von Klassen ermitteln, die zur gezielten Krankheitsprävention genutzt werden können.
Literatur
Bankhofer, Udo: Data Mining und seine betriebswirtschaftliche Relevanz. In: Betriebswirtschaftliche Forschung und Praxis (BFuP) (2004), Jg. 56, Heft 4, S. 395 – 412.
Gabriel, Roland ; Röhrs, Heinz-Peter: Gestaltung und Einsatz von Datenbanksystemen – Data Base Engineering und Datenbankarchitekturen. Springer : Berlin, Heidelberg 2003.
Gluchowski, Peter ; Gabriel, Roland ; Dittmar, Carsten: Management Support Systeme – Computergestützte Informationssysteme für Fach- und Führungskräfte. 2. Auflage. Springer : Berlin, Heidelberg 2008.
Grabmeier, Johannes: Segmentierende und clusterbildende Methoden. In: Hippner, Hajo ; Küsters, Ulrich ; Meyer, Matthias ; Wilde, Klaus (Hrsg.): Handbuch Data Mining im Marketing, Knowledge Discovery in Marketing Databases, S. 299 – 359. Vieweg : Braunschweig, Wiesbaden 2001.
Hippner, Hajo ; Schmitz, Berit: Data Mining in Kreditinstituten – Die Clusteranalyse zur zielgruppengerechten Kundenansprache. In: Hippner, Hajo ; Küsters, Ulrich ; Meyer, Matthias ; Wilde, Klaus (Hrsg.): Handbuch Data Mining im Marketing, Knowledge Discovery in Marketing Databases, S. 607 – 622. Vieweg : Braunschweig, Wiesbaden 2001.
Klein, Andreas: Multivariate Marktforschungsverfahren. In: Das Wirtschaftsstudium (Wisu) (2005), 34. Jg., Heft 3, S. 306 – 308.
Küsters, Ulrich: Data Mining Methoden: Einordnung und Überblick. In: Hippner, Hajo ; Küsters, Ulrich ; Meyer, Matthias ; Wilde, Klaus (Hrsg.): Handbuch Data Mining im Marketing, Knowledge Discovery in Marketing Databases, S. 95 – 130. Vieweg : Braunschweig, Wiesbaden 2001.
Markov, Zdravko ; Larose, Daniel: Data Mining the Web: Uncovering Patterns in Web Content, Structure, and Usage. Wiley & Sons : Hoboken, New Jersey 2007.
Mertens, Peter ; Wieczorrek, Hans Wilhelm: Data X Strategien – Data Warehouse, Data Mining und operationale Systeme für die Praxis. Springer : Berlin, Heidelberg 2000.
Petersohn, Helge: Data Mining – Verfahren, Prozesse, Anwendungsarchitektur. Oldenbourg : München 2005.